 29 Apr. 2025
29 Apr. 2025 In my previous blog, Supercharging Large Language Models through Model Merging, I explored the foundational concept of model merging and how it can enhance the capabilities of large language models. Now, I’m back with an update!
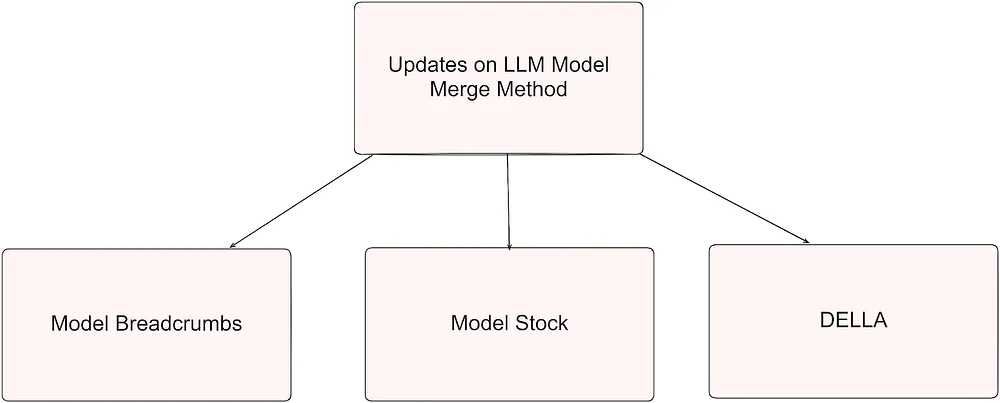
In this post, I delve into three exciting advancements in model merging techniques: Model Breadcrumbs, Model Stock, and DELLA. These approaches push the boundaries of what’s possible in natural language processing, each offering unique strategies for merging expert models, reducing interference, and improving performance.
- Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks
Research Paper: Model Breadcrumbs
- It is a proposed method aimed to construct multi-task models from pre-existing fine-tuned foundation models without additional training.
- It is a technique that helps combine the knowledge from multiple fine-tuned models into a single multi-task model.
- It does this by identifying and retaining the most important weight changes that occurred during fine-tuning for each task, while filtering out extreme or insignificant weight differences.
Process Overview:
- It starts with a pre-trained foundation model fine-tuned for various auxiliary tasks, denoted by weights ‘θ’.
- After fine-tuning on a specific task ‘t’, the weights become θ’t.
- The initial step involves creating task vectors by calculating weight differences between ‘θ’t’ and ‘θ’, resulting in ‘θdt’.
- The task vectors ‘θdt’ contain large outliers (significant deviations) and negligible differences (minor perturbations) from the foundation model’s weights.
- The presence of both large outliers (significant deviations) and negligible differences (minor perturbations) can impact the effectiveness of the resulting multi-task model upon merging.
- To address this, a masking process is introduced to filter out both large outliers and small perturbations.
Masking Operation:
- For each layer L, the extreme tails of the absolute magnitude distribution of ‘θdt’ are masked out using thresholds ‘γ’ and ‘β’ for the right and left tails, respectively.
- Weights wi^L (index of the weights in Layer L) are sorted (lowest to highest) by their absolute magnitude, and the mask for the layer L is defined based on these thresholds.
- Masked weights are either set to zero in ‘θdt’ or returned to their pre-training values θ’t.
- The masks (Layer-level mask) are aggregated over all layers for task t, resulting in the final mask (Task-level mask).
Applying Masks:
- The mask is applied to the task vectors ‘θdt’, creating a set of weight differences representing a trajectory in the weight space.
- This trajectory captures the knowledge gained during fine-tuning while filtering out perturbations.
Multi-Task Model Formation:
- For T tasks, a multi-task model θ* is created by following the trajectories defined by Model Breadcrumbs with a strength parameter α.
- This process is described in Equation 3 and Algorithm 1.
Algorithm Steps:
Input Data
- Foundation model (θ)
- Fine-tuned models (θ’t) for n tasks
- Parameters: α (strength), β and γ (thresholds)
For each task t (1 to n):
Step 1:
- Calculate task direction θdt = θ’t — θ (Difference between fine-tuned and base model)
Step 2:
For each layer in the model
- p = |θdt_layer| (Get absolute values of weight changes)
(Create tasks)
- m_top = mask_topk_percent(p, k=γ) (Mask large changes)
- m_bottom = mask_bottomk_percent(p, k=β) (Mask small changes)
- m_layer = merge_masks(m_top, m_bottom) (Combine masks)
- mt = stack_masks(all layer masks) (stack all layer masks into one mask for the task)
Final Multi-task Model Formation:
- θ* = θ + α * Σ(mt * θdt) where,
- θ is the base model.
- α controls how much to apply the changes.
- mt is the mask for task t.
- θdt is the weight changes for task t.
- Σ sums over all tasks.
Summary with example:
Let us consider starting point from foundational model fine-tuned for 3 tasks as:
Step1:
- Base Model (θ): [0.1, 0.2, 0.3, 0.4, 0.5]
- Fine-tuned Models:
Task1 (θ’t1): [0.15, 0.3, 0.28, 0.45, 0.7] // e.g., fine-tuned for Task 1
Task2 (θ’t2): [0.08, 0.35, 0.31, 0.38, 0.45] // e.g., fine-tuned for Task 2
Task3 (θ’t3): [0.12, 0.25, 0.35, 0.42, 0.6] // e.g., fine-tuned for Task 3
Step 2: Calculate Task Vectors (θdt):
- Task1 Vector (θdt1) = θ’t1 — θ
- = [0.05, 0.1, -0.02, 0.05, 0.2]
- Task2 Vector (θdt2) = θ’t2 — θ
- = [-0.02, 0.15, 0.01, -0.02, -0.05]
- Task3 Vector (θdt3) = θ’t3 — θ
- = [0.02, 0.05, 0.05, 0.02, 0.1]
Step 3: Layer-level Masking (For one layer example):
- Sort by magnitude and apply layer level masking
Task1:
- [0.05, 0.1, -0.02, 0.05, 0.2] (Before sorting)
- [0.02, 0.05, 0.05, 0.1, 0.2] (After sorting)
- mL1^β,γ = [0, 1, 1, 1, 0] // with β=1, γ=4
- β=1: Values at index ≤ 1 get mask=0 (0.02 gets 0), γ=4: Values at index ≥ 4 get mask=0 (0.2 gets 0)
Task2:
- [-0.02, 0.15, 0.01, -0.02, -0.05] (Before sorting)
- [0.01, 0.02, 0.02, 0.05, 0.15] (After sorting)
- mL2^β,γ = [0, 1, 1, 1, 0]
Task3:
- [0.02, 0.05, 0.05, 0.02, 0.1] (Before sorting)
- [0.02, 0.02, 0.05, 0.05, 0.1] (After sorting)
- mL3^β,γ = [0, 1, 1, 1, 0]
- Note:
- β (lower threshold):
- It determines the smallest magnitude value to consider.
- It sets a minimum threshold, masking out values smaller than or equal to it.
- γ (upper threshold):
- It represents the largest magnitude index to consider.
- It sets a cap, masking out values above this index once sorted.
- Purpose of Sorting:
- Sorting arranges the task vector values from smallest to largest magnitudes. This helps to distinguish between minor (likely noise or low-impact) changes and major changes (which are more likely to represent important task-specific adaptations).
Step 4: Task-level Masks (Aggregating all layers):
- Task1 Final Mask (mt1^β,γ) = stack_masks(all Layer1 masks)
- [0, 1, 1, 1, 0]
- Task2 Final Mask (mt2^β,γ) = stack_masks(all Layer2 masks)
- [0, 1, 1, 1, 0]
- Task3 Final Mask (mt3^β,γ) = stack_masks(all Layer3 masks)
- [0, 1, 1, 1, 0]
Step 5: Apply Masks to Task Vectors — θdt:
Masked Task1
- Before applying Mask to Task1 Vector θdt = [0.05, 0.1, -0.02, 0.05, 0.2]
- After applying Mask [0,1,1,1,0] to Task1, Masked Task1 = [0, 0.1, -0.02, 0.05, 0]
Masked Task2
- Before applying Mask to Task2 Vector θdt = [-0.02, 0.15, 0.01, -0.02, -0.05]
- After applying Mask [0,1,1,1,0] to Task2, Masked Task2 = [0, 0.15, 0.01, -0.02, 0]
Masked Task3
- Before applying Mask to Task3 Vector θdt = [0.02, 0.05, 0.05, 0.02, 0.1]
- After applying Mask [0,1,1,1,0] to Task3, Masked Task3 = [0, 0.05, 0.05, 0.02, 0]
Step 6: Final Multi-task Model Formation (with α = 0.5):
- θ* = θ + α * Σ(masked task vectors)
- θ* = [0.1, 0.2, 0.3, 0.4, 0.5] + 0.5 * ([0, 0.1, -0.02, 0.05, 0] (Task1 contribution) + [0, 0.15, 0.01, -0.02, 0] (Task2 contribution) +
[0, 0.05, 0.05, 0.02, 0]) (Task3 contribution) - θ* = [0.1, 0.2, 0.3, 0.4, 0.5] + 0.5 * [0, 0.3, 0.04, 0.05, 0]
- Final θ* = [0.1, 0.35, 0.32, 0.425, 0.5]
This shows how the algorithm:
- Takes one base model.
- Processes three different fine-tuned versions.
- Calculates and filters changes for each task.
- Combines everything into one multi-task model.
- Uses α to control how strongly the changes are applied.
Advantages
Efficient Multi-Task Learning:
- Avoids costly additional training.
- Combines pre-existing models into one robust multi-task model.
Improved Performance:
- The method has been shown to enhance performance across multiple tasks simultaneously.
- By selectively merging the knowledge from fine-tuned models, it can outperform individual fine-tuned models on specific tasks.
Scalability:
- The approach scales well with larger models and an increasing number of tasks.
- Experiments indicate that larger models benefit more from Model Breadcrumbs, reducing the performance gap between merged and fine-tuned models.
Versatility:
- Model Breadcrumbs is applicable to various domains and modalities, as demonstrated by its effectiveness in NLP tasks.
- This versatility allows it to be used in different fields and with different types of data.
Utilization of Existing Models:
- The method capitalizes on the growing pool of publicly available fine-tuned models, enabling practitioners to repurpose these resources effectively without needing access to original training data
Cons
Dependence on Initial Fine-Tuned Models:
- The performance of Model Breadcrumbs heavily relies on the quality of the initial fine-tuned models.
- If these models exhibit poor generalization or severe overfitting, such issues can propagate through the merging process, negatively impacting the final multi-task model.
Accumulation of Noise:
- As more tasks are merged, there is a risk of accumulating noise from the various fine-tuned models, which can potentially degrade performance if not managed properly.
Hyperparameter Tuning for Many Tasks:
- While the method generalizes hyperparameters well, it still requires initial hyperparameter tuning for the first few tasks.
- As the number of tasks increases, this tuning process might become more complex.
Task Compatibility:
- The success of Model Breadcrumbs may depend on the compatibility of the tasks being merged. Some tasks might be more challenging to combine effectively due to differences in their learning objectives.
Computational Cost:
- While Model Breadcrumbs is efficient in terms of not requiring additional training, the process of merging models and calculating weight differences can still incur computational costs, especially for large models.
Lack of Task-Specific Adaptation:
- Model Breadcrumbs focuses on merging models without additional training, which means it may not capture task-specific nuances as effectively as fine-tuning a model for each individual task.
2. Model Stock: All we need is just a fine-tuned models
Research Paper: Model Stock
- Model Stock introduces an efficient weight merging method that reduces the reliance on multiple fine-tuned models while enhancing performance in both in-distribution (ID) and out-of-distribution (OOD) tasks.
- In-distribution (ID) tasks: It involve data points that are drawn from the same distribution as the training data. This means that the model has seen similar examples during its training phase.
- Out-of-distribution (OOD) tasks: It involve data points that do not conform to the distribution of the training data. These are instances that the model has not encountered during training and may differ significantly from ID examples.
- The Model Stock approach focuses on cost-efficient weight merging, addressing the computational challenges associated with traditional methods that often require averaging multiple fine-tuned models.
Method Overview:
Key Points
Objective:
- The goal is to get closer to the center of the weight distribution (µ) because it was observed that weights closer to µ correlate with better performance.
- Directly calculating µ by averaging many fine-tuned models is computationally expensive (as done in Model Soup / Linear Model).
- Model Stock aims to approximate µ efficiently using fewer models.
- The goal is to approximate a weight wH that is closer to the center μ of the weight distribution.
Weight Distribution:
- Fine-tuned model weights, even with different random seeds, consistently reside close to a central point within a thin, shell-like region of weight space.
Performance Correlation:
- Model performance (both ID and OOD) improves as weights get closer to the center of this distribution
Efficient Approximation:
- Model Stock efficiently estimates this central point (µ) using a small number of fine-tuned models and leveraging the pre-trained model’s weights, avoiding the computational cost of extensive model averaging.
Utilization of Pre-trained Models:
- A pre-trained model’s weights (w₀) as an “anchor point / reference.”
- Pre-trained models offer general knowledge and robustness, making them a suitable reference.
Layer-wise Weight Averaging:
- The method employs a layer-wise weight averaging technique, which simplifies the optimization process. Instead of requiring extensive fine-tuning or heuristic parameter settings, Model Stock calculates an optimal interpolation ratio based solely on the angle between the fine-tuned models.
- This approach eliminates the need for additional training or complex adjustments, making it more accessible and efficient.
Geometric Conditions for weight Approximation:
- The paper outlines specific geometric conditions that must be satisfied for effective weight approximation:
Condition 1:
- The relationship between the weights must form an isosceles right triangle, ensuring that the average weight lies near the center.
- It ensures that the fine-tuned weights are symmetrically positioned around the center point, allowing for effective averaging.
Condition 2:
- The perpendicular distance from the center of distribution to the plane formed by the pre-trained and fine-tuned weights must be minimized.
- It ensures that the pre-trained model’s weight contributes optimally to finding a point close to the center of distribution based on its relationship with the average of the fine-tuned weights.
Mathematical Expression:
- For two fine-tuned models w1 and w2 the average weight is defined as: w12 = (w1+w2)/2
- To find the weight closed to the center, two conditions must be satisfied:
Condition 1: The vectors must form an isosceles right triangle:
- (w1−μ)⊥(w2−μ) and ∣∣wi−μ∣∣=∣∣w2−μ∣∣
Orthogonality: (w1−μ)⊥(w2−μ)
- This means that the vector from μ to w1 is perpendicular to the vector from μ to w2. In geometric terms, this indicates that these two vectors form a right angle at the center μ.
Equal Distance: ∣∣wi−μ∣∣=∣∣w2−μ∣∣
- This condition states that the distances from w1 and w2 to the center μ are equal, which is a characteristic of an isosceles triangle (where two sides are of equal length).
Condition 2: The perpendicular distance from w0 to the plane formed by w1 and w2:
- (w0−μ)⊥(w12−μ)
- Here, w12 represents the average weight between w1 and w2. This condition means that the vector from the pre-trained model weight w0 to the center μ must be perpendicular to the vector from w12 to μ.
The position of wH can be expressed using the interpolation ratio t, where t=2cosθ/1+cosθt is determined solely by the angle θ between the two fine-tuned models.
- wH=(2cosθ/1+cosθ)w12+(1−(2cosθ/1+cosθ))w0
- Here, w0 is the weight from the pre-trained model, and θ is the angle between w1 and w2.
For Multiple Fine-tuned Models:
- For N fine-tuned models, define the averaged weight:
- The closest weight wH(N) to the center can be derived as:
- The interpolation ratio for multiple models is given by:
Periodic Merging (During Training)
- It is an innovative aspect of Model Stock, where weights are merged at regular intervals during training. This allows for real-time optimization of weights while maintaining parallelism in training and merging processes.
- By strategically merging weights at each epoch’s end based on current angles between models, Model Stock can more accurately approximate optimal weights throughout training.
- Iterative Refinement: To further refine weights during training, Model Stock proposes merging at the end of each epoch.
- Parallelism: This merging process can run in parallel with the fine-tuning of the models for the next epoch.
- Dynamic Angle: The angle θ is recalculated at each epoch based on the current weights.
Pros:
Reduced Computational Requirements
- Model Stock significantly decreases the need for multiple fine-tuned models, allowing for effective model optimization using as few as two models.
- This reduction in model count leads to lower computational costs and resource usage compared to traditional methods like Model Soup / Linear, which often require dozens of models.
Enhanced Performance
- The method has been shown to achieve comparable or superior performance on both in-distribution (ID) and out-of-distribution (OOD) tasks.
- For instance, it achieved an impressive 87.8% top-1 accuracy on ImageNet and an average of 74.9% across five distribution shift benchmarks.
Simplified Optimization Process:
- By employing a layer-wise weight averaging technique and calculating an optimal interpolation ratio based solely on the angle between fine-tuned models, Model Stock simplifies the fine-tuning process.
- This eliminates the need for extensive additional training or complex parameter adjustments, making it more accessible for practitioners.
Geometric Insights Utilization:
- The method leverages geometric properties of weight distributions in weight space, which can lead to more informed and effective weight merging strategies compared to traditional averaging techniques.
Efficiency in Training:
- The periodic merging of weights during training allows for real-time optimization, further enhancing efficiency and potentially leading to better convergence during the training process.
Cons:
Dependency on Fine-Tuned Models
- While using only two fine-tuned models can be advantageous, it may limit the method’s robustness in scenarios where more diverse model configurations could provide better generalization across tasks.
- If the two models are not sufficiently representative of the task variability, performance may suffer.
Potential Overfitting Risks:
- Relying heavily on a minimal number of fine-tuned models could lead to overfitting if those models are not adequately diverse or if they capture noise rather than meaningful patterns from the training data.
Limited Applicability in Highly Variable Domains:
- In domains where data distributions change significantly or where there is high variability in input data, having only a couple of models may not capture the necessary breadth of information needed for robust performance.
Complexity in Angle Calculation:
- The requirement to calculate angles between model weights may introduce additional complexity, particularly if practitioners are not familiar with geometric interpretations in high-dimensional weight spaces.
Need for Accurate Pre-trained Models:
- The effectiveness of Model Stock is contingent upon the quality and relevance of the pre-trained model used as an anchor point. If the pre-trained model is not well-suited to the specific task, it may negatively impact performance despite the advantages offered by the method.
3. DELLA: Drop and rEscale via sampLing with mAgnitude
Research Paper: DELLA
- DELLA merging is a novel approach for merging homologous models, which are models fine-tuned from the same base model for different tasks.
- It is an acronym for Drop and rEscaLe via sampLing with mAgnitude.
Methodology:
Key notations:
- Expert Models: It is denoted as ‘Mt’ with parameters ‘θt’, where ‘t’ signifies the specific task expertise.
- Base Model: It is a common base model ‘M’ fine-tuned for each task, resulting in expert models.
- Delta Parameters: Defined as the difference between expert and base model parameters: ‘δt:=θt−θ’.
DELLA Merging is a three-step process for model merging: Drop, Elect, and Fuse.
Step 1 (Drop):
- Purpose: The goal of this step is to reduce interference among expert models while maintaining task-specific performance.
- MagPrune: This step introduces MAGPRUNE, a novel magnitude-based pruning method that assigns higher dropout probabilities to lower magnitude delta parameters, followed by rescaling the remaining parameters.
- The taller the delta parameter (larger magnitude), the LOWER its probability of being dropped.
- The shorter the delta parameter (smaller magnitude), the HIGHER its probability of being dropped.
In the Figure 2:
- δ2 has the largest magnitude → gets lowest drop probability (p-Δ).
- δ1 has medium magnitude → gets medium drop probability (p).
- δ3 has smallest magnitude → gets highest drop probability (p+Δ).
- Larger delta parameters likely represent more important changes from the base model so by giving them lower drop probabilities, its more likely to keep the important changes.
- Smaller delta parameters might be less crucial, so it’s more likely to drop them.
Pruning Mechanism:
- Each delta parameter is assigned a drop probability Pd={p1,p2,…,pn} based on its magnitude, with higher magnitudes having lower probabilities of being dropped.
Hyperparameter Δ:
- It uses a hyperparameter Δ to control the difference between consecutive drop probabilities.
Scaling:
- Remaining delta parameters are rescaled by 1/(1−pi), where pi is the probability of drop of weight δi, to compensate for the effect of pruning.
Step 2 (Elect):
Purpose:
- The objective of this step is to select delta parameters that will participate the merging operation to minimize further interference.
- This step selects delta parameters for merging by considering their signs, aiming to minimize directional discrepancy.
Directional Selection:
- The method identifies the dominant direction by calculating the sign of the sum of all delta parameters at each position k:
- It creates set C = {t ∈ [T] | sgn(δtk) = S} containing indices of parameters with matching signs.
- The formula C = {t ∈ [T] | sgn(δtk) = S} means:
- Look at all experts (t ∈ [T]).
- Check if each expert’s parameter sign matches S.
- If it matches, include that expert’s index in set C.
Step 3 (Fuse):
Purpose
- To combine the elected parameters to create the final merged model.
- The elected delta parameters are averaged to obtain the merged delta parameter, and the final merged model is obtained by adding the scaled delta parameters to the base model parameters.
- It computes average of elected delta parameters (δkavg) at position k as:
- Applies scaling factor λ to compensate for dropped parameters.
- Final merged model parameters: θm = θ + λ * δavg.
Pros
Improved Performance:
- DELLA achieves an average improvement of 2.4 points over baseline methods that utilize pruning techniques (such as DARE and TIES) and 11.1 points over methods without pruning (TA) in model merging tasks.
Effective Interference Reduction:
- The method effectively reduces interference among expert models through its three-step process: Drop, Elect, and Fuse, allowing for better retention of task-specific performance during merging.
Magnitude-Based Pruning:
- The introduction of MAGPRUNE, a novel pruning method that samples delta parameters based on their magnitudes, allows for a more strategic approach to parameter selection compared to random or uniform methods used in other techniques.
Flexibility:
- DELLA can encompass existing methods like NODROP, DARE, and TIES by adjusting hyperparameters, making it adaptable to various scenarios and model architectures.
High Accuracy in Merges:
- DELLA achieved the highest average score for 5 out of 8 merges and the second-best score for 2 out of 3 remaining merges, demonstrating its effectiveness across different datasets and tasks.
Cons
Complexity of Hyperparameters:
- DELLA has more hyperparameters compared to other baseline methods like DARE and TIES, which adds complexity to the process of finding optimal merging configurations.
- This may require extensive tuning and experimentation to achieve the best results.
Limited Backbone Compatibility:
- Similar to DARE and TIES, DELLA is only effective for models with the same backbone architecture.
- This limitation restricts its applicability when attempting to merge models with different pre-trained backbones.
Computational Constraints:
- Due to computational limitations and a limited number of available models for evaluation, the authors could not extensively assess the performance of DELLA across various model architectures and sizes, which may affect generalizability.
Potential Overfitting Risks:
- The reliance on hyperparameter tuning may lead to overfitting if not managed carefully, particularly in scenarios with limited data or when applying the method across diverse datasets.
Need for Further Validation:
- While the results are promising, further validation across a wider range of applications and model types is needed to fully establish the robustness and versatility of the DELLA method in practical settings.
Implementing Sample Code — Testing each method
To implement code, a mergekit is used.
- Mergekit is a comprehensive, open-source library designed to facilitate merging large language models (LLMs).
- It offers functionalities that combine the strengths of multiple pre-trained or fine-tuned LLMs into a single, potentially more powerful model.
- Merges can be run entirely on the CPU or accelerated with as little as 8 GB of VRAM.
Github source: https://github.com/arcee-ai/mergekit
Research Paper: https://arxiv.org/pdf/2403.13257.pdf
STEP 1
- In order to perform a merge operation, we first have to clone and install the mergekit library.
STEP 2
- We create a YAML config file for each of the methods as follows:
- YAML is a human readable data serialization format used for storing and configuring data.
- It’s often used for configuration files due to its simplicity and ease of editing compared to complex file formats like JSON or XML.
STEP 3
- Now we use mergekit-yaml cli tool to merge the models for the respective methods.
Finally, the respective merged model are stored in the merge Folder (This is an example of one method)
Resource and Time required for each method while running on Google Colab CPU
- Model-Breadcrumbs method
2. Model-Stock method
3. DELLA method
Inference of each method
- Inference on Model-Breadcrumbs method
2. Inference on Model-Stock method
3. Inference on DELLA method
 Filter
Filter