 06 May. 2025
06 May. 2025 CloudFront logs are a powerful tool for understanding user traffic patterns, requests, and overall interaction with your application. However, raw logs don’t provide much actionable insight on their own.
To make these logs more useful, we can enrich them with additional data, such as geographic location based on IP addresses (GeoIP), as well as device and browser information extracted from user-agent strings.
In this guide, we’ll walk through how to build an Apache Beam pipeline in Java to enrich CloudFront logs, using two key steps:
- Syncing GeoIP data from a CSV file to a PostgreSQL database.
- Reading daily CloudFront logs from S3, enriching them with device, browser, and GeoIP data, and saving the enriched data back into the PostgreSQL database.
Let’s dive in!
What is Apache Beam?
Before we jump into the implementation, it’s important to understand what Apache Beam is and why it’s the ideal tool for building data pipelines.
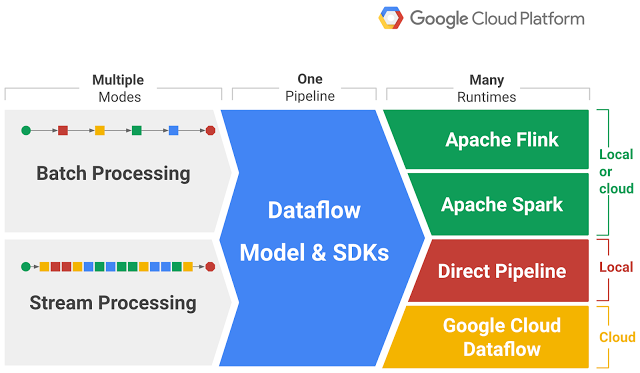
Apache Beam is a unified, open-source model for defining both batch and streaming data processing pipelines. It provides a consistent API for writing pipelines in various languages, including Java, Python, and Go.
Apache Beam’s main strength lies in its ability to run pipelines on multiple execution engines, or “runners,” such as:
- Google Cloud Dataflow: A fully managed service for stream and batch data processing on Google Cloud.
- Apache Flink: A distributed stream processing framework.
- Apache Spark: A fast engine for large-scale data processing.
- Direct Runner: For running pipelines locally for testing and development purposes.Overview of Apache Beam

Key Benefits of Apache Beam
- Portability: Write once, run anywhere. The same Beam pipeline can be run on different runners, making it extremely flexible.
- Unified Model: It supports both batch and stream processing, allowing you to handle different data scenarios within the same framework.
- Extensibility: With its rich set of I/O connectors, you can easily connect to cloud storage systems (e.g., Amazon S3, Google Cloud Storage), databases (e.g., PostgreSQL, MySQL), and more.
- Scalability: Beam pipelines can scale horizontally, making it suitable for large-scale data processing.
In this post, we use Apache Beam with Java to build two pipelines: one for syncing GeoIP data and another for enriching CloudFront logs.
Step 1: Syncing GeoIP Data from CSV to PostgreSQL
GeoIP data allows us to map IP addresses to geographic locations, such as country, region, and city.
To ensure that we always have accurate and up-to-date location data, we need to sync this information periodically (e.g., weekly) from a CSV file to a PostgreSQL database.
Pipeline Overview
In the first pipeline, we will:
- Read the GeoIP CSV file.
- Parse the CSV data into Java objects.
- Write the parsed data to a PostgreSQL table.

Setting Up the PostgreSQL Table
Before we begin, we need a PostgreSQL table to store the GeoIP data. Here’s a simple schema:
CREATE TABLE IF NOT EXISTS city_location
(
geoname_id INTEGER primary key,
locale_code VARCHAR(255),
continent_code VARCHAR(255),
continent_name VARCHAR(255),
country_iso_code VARCHAR(255),
country_name VARCHAR(255),
subdivision1_iso_code VARCHAR(255),
subdivision1_name VARCHAR(255),
subdivision2_iso_code VARCHAR(255),
subdivision2_name VARCHAR(255),
city_name VARCHAR(255),
metro_code VARCHAR(255),
time_zone VARCHAR(255)
);
CREATE TABLE network_location
(
id serial primary key,
network inet,
geoname_id INTEGER,
registered_country_geoname_id INTEGER,
represented_country_geoname_id INTEGER,
is_anonymous_proxy BOOLEAN,
is_satellite_provider BOOLEAN,
postal_code VARCHAR(255),
latitude DOUBLE PRECISION,
longitude DOUBLE PRECISION,
accuracy_radius INTEGER
);
CREATE INDEX idx_network on network_location (network);
Implementing the Pipeline
Create a DTO called NetworkLocation and CityLocation
// Import excluded for brevity
@AutoValue
@DefaultCoder(SchemaCoder.class)
@DefaultSchema(AutoValueSchema.class)
public abstract class NetworkLocation {
@Nullable
public abstract String getNetwork();
@Nullable
public abstract Integer getGeonameId();
@Nullable
public abstract Integer getRegisteredCountryGeonameId();
@Nullable
public abstract Integer getRepresentedCountryGeonameId();
@Nullable
public abstract Boolean getIsAnonymousProxy();
@Nullable
public abstract Boolean getIsSatelliteProvider();
@Nullable
public abstract String getPostalCode();
@Nullable
public abstract Double getLatitude();
@Nullable
public abstract Double getLongitude();
@Nullable
public abstract Integer getAccuracyRadius();
public static Builder builder() {
return new AutoValue_NetworkLocation.Builder();
}
@AutoValue.Builder
public abstract static class Builder {
public abstract Builder setNetwork(String network);
public abstract Builder setGeonameId(@Nullable Integer geonameId);
public abstract Builder setRegisteredCountryGeonameId(@Nullable Integer registeredCountryGeonameId);
public abstract Builder setRepresentedCountryGeonameId(@Nullable Integer representedCountryGeonameId);
public abstract Builder setIsAnonymousProxy(Boolean isAnonymousProxy);
public abstract Builder setIsSatelliteProvider(Boolean isSatelliteProvider);
public abstract Builder setPostalCode(@Nullable String postalCode);
public abstract Builder setLatitude(@Nullable Double latitude);
public abstract Builder setLongitude(@Nullable Double longitude);
public abstract Builder setAccuracyRadius(@Nullable Integer accuracyRadius);
public abstract NetworkLocation build();
}
}
@AutoValue
@DefaultSchema(AutoValueSchema.class)
@DefaultCoder(SchemaCoder.class)
public abstract class CityLocationDto{
@Nullable
public abstract Integer getGeonameId();
@Nullable
public abstract String getLocaleCode();
@Nullable
public abstract String getContinentCode();
@Nullable
public abstract String getContinentName();
@Nullable
public abstract String getCountryIsoCode();
@Nullable
public abstract String getCountryName();
@Nullable
public abstract String getSubdivision1IsoCode();
@Nullable
public abstract String getSubdivision1Name();
@Nullable
public abstract String getSubdivision2IsoCode();
@Nullable
public abstract String getSubdivision2Name();
@Nullable
public abstract String getCityName();
@Nullable
public abstract String getMetroCode();
@Nullable
public abstract String getTimeZone();
public static Builder builder() {
return new AutoValue_CityLocationDto.Builder();
}
@AutoValue.Builder
public abstract static class Builder {
public abstract Builder setGeonameId(Integer geonameId);
public abstract Builder setLocaleCode(String localeCode);
public abstract Builder setContinentCode(String continentCode);
public abstract Builder setContinentName(String continentName);
public abstract Builder setCountryIsoCode(String countryIsoCode);
public abstract Builder setCountryName(String countryName);
public abstract Builder setSubdivision1IsoCode(String subdivision1IsoCode);
public abstract Builder setSubdivision1Name(String subdivision1Name);
public abstract Builder setSubdivision2IsoCode(String subdivision2IsoCode);
public abstract Builder setSubdivision2Name(String subdivision2Name);
public abstract Builder setCityName(String cityName);
public abstract Builder setMetroCode(String metroCode);
public abstract Builder setTimeZone(String timeZone);
public abstract CityLocationDto build();
}
}
Here we are using Google AutoValue. Using AutoValue with Apache Beam simplifies the creation of immutable data transfer objects (DTOs) by reducing boilerplate code and ensuring consistency. It also enhances type safety and readability, making your Beam pipelines easier to maintain and debug.
Now, let’s create the GeoIP pipeline.
public class GeoIpPipeline {
private static final Logger log = LoggerFactory.getLogger(GeoIpPipeline.class);
private static final String CITY_LOCATION_SQL = """
INSERT INTO city_location (geoname_id, locale_code, continent_code, continent_name,
country_iso_code, country_name, subdivision1_iso_code, subdivision1_name,
subdivision2_iso_code, subdivision2_name, city_name, metro_code, time_zone)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""";
private static final String NETWORK_LOCATION_SQL = """
INSERT INTO network_location (network, geoname_id, registered_country_geoname_id, represented_country_geoname_id,
is_anonymous_proxy, is_satellite_provider, postal_code, latitude, longitude,
accuracy_radius)
VALUES (cast(? as inet), ?, ?, ?, ?, ?, ?, ?, ?, ?)
""";
public static void main(String[] args) {
GeoIpOptions options = PipelineOptionsFactory
.fromArgs(args)
.withValidation()
.as(GeoIpOptions.class);
JdbcIO.DataSourceConfiguration dbConfig = JdbcIO.DataSourceConfiguration.create(options.getJdbcDriver(), options.getJdbcUrl())
.withUsername(options.getDbUser())
.withPassword(options.getDbPassword());
Pipeline pipeline = Pipeline.create(options);
pipeline
.apply("Load City Locations", TextIO.read()
.from(options.getCityLocationS3())
.withSkipHeaderLines(1)
)
.apply("Convert to Dto", MapElements
.into(TypeDescriptor.of(CityLocationDto.class))
.via(new CsvToCityLocation()))
.apply("Write City Location to DB", JdbcIO.<CityLocationDto>write()
.withDataSourceConfiguration(dbConfig)
.withStatement(CITY_LOCATION_SQL)
.withPreparedStatementSetter(new CityLocationPreparedStatementSetter())
);
pipeline.apply(Create.of(Arrays.asList(options.getNetworkLocationS3().split(","))))
.apply("Load Network Locations", FileIO.matchAll())
.apply(FileIO.readMatches())
.apply(TextIO.readFiles().withSkipHeaderLines(1))
.apply("Convert to Dto", MapElements
.into(TypeDescriptor.of(NetworkLocation.class))
.via(new CsvToNetworkLocation()))
.apply("Write Network Location to DB", JdbcIO.<NetworkLocation>write()
.withDataSourceConfiguration(dbConfig)
.withStatement(NETWORK_LOCATION_SQL)
.withPreparedStatementSetter(new NetworkLocationPreparedStatementSetter())
);
pipeline.run().waitUntilFinish();
}
}
In this code:
- We read the GeoIP CSV file using
TextIO.read(). - We parse the CSV into NetworkLocation and CityLocation objects using a custom
MapElements. - Finally, we use JdbcIO.write() to insert or update the data in the PostgreSQL table.
Ideally this, pipeline should be run once a week so that the GeoIp data is not out of sync.
Step 2: Reading and Enriching CloudFront Logs
The second pipeline is where the real magic happens. We will:
- Read raw CloudFront logs from S3.
- Extract useful information such as IP addresses and user-agent strings.
- Enrich the logs with:
- GeoIP data by querying PostgreSQL.
- Device and browser data using the user-agent string.
4. Save the enriched data back into PostgreSQL for analysis.
Here is the architecture of this pipeline:

Setting Up the PostgreSQL Table for Enriched Logs
We need a new table to store the enriched CloudFront logs:
CREATE TABLE IF NOT EXISTS cloudfront_logs
(
id serial8 primary key,
date DATE,
time time,
x_edge_location varchar(255),
sc_bytes BIGINT,
c_ip inet,
cs_method varchar(10),
cs_host varchar(50),
cs_uri_stem varchar(255),
sc_status INT,
cs_referrer varchar(255),
cs_user_agent text,
os varchar(50),
browser varchar(50),
device_type varchar(20),
cs_uri_query varchar(255),
cs_cookie text,
x_edge_result_type varchar(255),
x_edge_request_id varchar(100),
x_host_header varchar(100),
cs_protocol varchar(20),
cs_bytes BIGINT,
time_taken NUMERIC,
x_forwarded_for varchar(100),
ssl_protocol varchar(255),
ssl_cipher varchar(255),
x_edge_response_result_type varchar(20),
cs_protocol_version varchar(155),
fle_status varchar(20),
fle_encrypted_fields varchar(255),
c_port INT,
time_to_first_byte NUMERIC,
x_edge_detailed_result_type varchar(100),
sc_content_type varchar(50),
sc_content_len BIGINT,
sc_range_start BIGINT,
sc_range_end BIGINT
);
Implementing the Pipeline
Here’s how to implement the pipeline that reads, enriches, and writes the CloudFront logs:
public class PipelineMain {
private static final Logger log = LoggerFactory.getLogger(PipelineMain.class);
private static final SimpleDateFormat DATE_FORMAT = new SimpleDateFormat("yyyy-MM-dd");
private static final AtomicInteger COUNTER = new AtomicInteger();
private static final String CLOUDFRONT_LOG_INSERT = """
INSERT INTO cloudfront_logs (
date, time, x_edge_location, sc_bytes, c_ip, cs_method, cs_host,
cs_uri_stem, sc_status, cs_referrer, cs_user_agent, cs_uri_query,
cs_cookie, x_edge_result_type, x_edge_request_id, x_host_header,
cs_protocol, cs_bytes, time_taken, x_forwarded_for, ssl_protocol,
ssl_cipher, x_edge_response_result_type, cs_protocol_version,
fle_status, fle_encrypted_fields, c_port, time_to_first_byte,
x_edge_detailed_result_type, sc_content_type, sc_content_len,
sc_range_start, sc_range_end, os, browser, device_type)
VALUES (?, ?, ?, ?, CAST(? AS inet), ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""";
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory
.fromArgs(args)
.withValidation()
.as(PipelineOptions.class);
final var date = options.getDate() != null ? options.getDate() : new Date(System.currentTimeMillis());
log.info("Pipeline options: {}", options);
JdbcIO.DataSourceConfiguration dbConfig = JdbcIO.DataSourceConfiguration.create(options.getJdbcDriver(), options.getJdbcUrl())
.withUsername(options.getDbUser())
.withPassword(options.getDbPassword());
var pipeline = Pipeline.create(options);
var cloudFrontLogs = pipeline.apply("Read from S3", TextIO.read()
.from(format("s3://%s/*", options.getS3Bucket()))
)
.apply("Convert to DTO", ParDo.of(new DoFn<String, CloudFrontDto>() {
@ProcessElement
public void processElement(ProcessContext c) {
var line = c.element();
if (isBlank(line) || line.startsWith("#")) return;
c.output(new TsvToCloudFrontDtoTransformer().apply(c.element()));
}
}))
.apply("Enrich Device Info", MapElements
.into(TypeDescriptor.of(CloudFrontDto.class))
.via((SerializableFunction<CloudFrontDto, CloudFrontDto>) input -> {
if (input == null || input.getCsUserAgent() == null) return input;
var userAgent = new UserAgent(URLDecoder.decode(input.getCsUserAgent(), StandardCharsets.UTF_8));
var os = userAgent.getOperatingSystem().getGroup().getName();
var browser = userAgent.getBrowser().getGroup().getName();
var deviceType = userAgent.getOperatingSystem().getDeviceType().getName();
return input.toBuilder()
.setOs(os)
.setBrowser(browser)
.setDeviceType(deviceType)
.build();
})
);
// Write Logs to DB
cloudFrontLogs.apply("Write Logs to DB", JdbcIO.<CloudFrontDto>write()
.withDataSourceConfiguration(dbConfig)
.withStatement(CLOUDFRONT_LOG_INSERT)
.withPreparedStatementSetter(new CloudfrontLogPreparedStatementSetter())
);
pipeline.run().waitUntilFinish();
}
public static Date getSqlDate(LocalDate date) {
var time = date.atStartOfDay()
.atZone(ZoneId.systemDefault())
.toInstant()
.toEpochMilli();
return new Date(time);
}
}
Explanation
- Reading CloudFront Logs: We start by reading the raw CloudFront logs from an S3 bucket using
TextIO.read(). Each log is parsed into aCloudFrontLogobject. - GeoIP Enrichment: We extract the IP addresses from the logs and query the GeoIP PostgreSQL table to retrieve the corresponding geographic locations.
- User-Agent Enrichment: We extract user-agent strings from the logs and use a user-agent parsing library to derive device and browser information.
- Writing to PostgreSQL: Finally, the enriched log data is written to the PostgreSQL enriched_logs table.
Conclusion
In this article, we walked through the process of enriching CloudFront logs with GeoIP, device, and browser information using an Apache Beam pipeline written in Java.
With Apache Beam, we can efficiently process and enrich large-scale data from multiple sources. This enriched data provides much more actionable insights and can be used to enhance reporting, analytics, and decision-making processes.
By utilizing Beam’s scalability and flexibility, you can extend this architecture further to process even more types of data and handle complex business logic in your data pipelines.
Feel free to experiment with additional enrichment strategies, optimizations, or even integration with machine learning models for predictive analysis.
Future Enhancement
- Although the PostgreSQL is a powerful database, we could choose a more suitable storage engine such as Elasticsearch which is more suitable for these types of work.
- Use Kibana from Elasticsearch to create powerful dashboards for the visualization.
 Filter
Filter